Knitting Trends as observed from Raverly
Raverly is one of my favorite places to spend time as a yarn enthusiast. It’s a social media and e-commerce site rolled into one. The best part is the community driven project pages where others share finished object photos, notes, and yarns used.
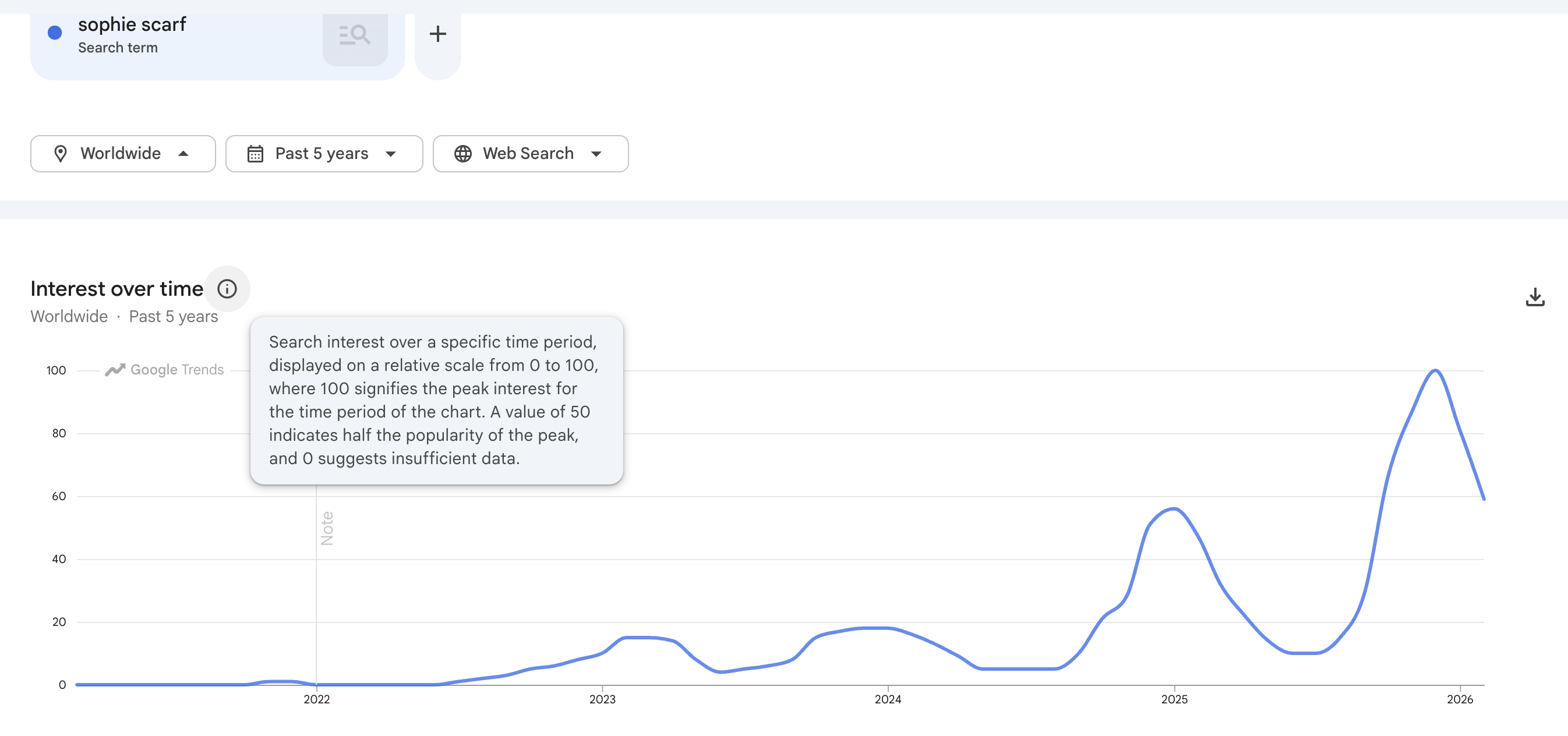
Perhaps it’s frequency illusion, but fibre arts appear to be everywhere nowadays. Based on a quick look on Google Trends: the Sophie Scarf (a simple cashmere scarf tie) had it’s peak popularity this winter season (2025) despite the pattern being release since July 2022!
Raverly has a “Hot Right Now” section of most visited patterns in the last 24 hours. I set up an AWS lambda process to query the patterns from the API once per day. I got the idea from a blog [1] so I pass the information on too!
import csv
import io
import json
import boto3
import os
from datetime import datetime, timezone
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.mime.base import MIMEBase
from email import encoders
import requests
# --- Config from Lambda environment variables ---
RAVELRY_USER = os.environ["RAVELRY_USER"]
RAVELRY_PASS = os.environ["RAVELRY_PASS"]
EMAIL_TO = os.environ["EMAIL_TO"]
EMAIL_FROM = os.environ["EMAIL_FROM"]
S3_BUCKET = os.environ["S3_BUCKET"]
SES_REGION = os.environ.get("SES_REGION", "us-east-1")
SEARCH_PARAMS = {
"page_size": 100,
"sort": "recently_popular",
}
s3 = boto3.client("s3")
ses = boto3.client("ses", region_name=SES_REGION)
# ---------------------------------------------------------------
# Step 1 - Search for most popular patterns, preserve rank order
# ---------------------------------------------------------------
def fetch_ranked_ids() -> list:
"""
Query /patterns/search.json and return pattern IDs in rank order.
Position 0 = rank 1, position 1 = rank 2, etc.
"""
resp = requests.get(
"https://api.ravelry.com/patterns/search.json",
auth=(RAVELRY_USER, RAVELRY_PASS),
# params=SEARCH_PARAMS,
timeout=25,
)
resp.raise_for_status()
patterns = resp.json().get("patterns", [])
ids = [p["id"] for p in patterns]
print(f"Step 1 complete: {len(ids)} pattern IDs fetched")
return ids
# ---------------------------------------------------------------
# Step 2 - Fetch full pattern details for all IDs in one call
# ---------------------------------------------------------------
def fetch_pattern_details(ids: list) -> dict:
"""
Query /patterns.json?ids=id1+id2+... to get full pattern objects.
Returns a dict keyed by string pattern id for easy lookup.
NOTE: ids must be appended directly to the URL string — NOT passed via
the params dict. requests encodes + as %2B which breaks the Ravelry API.
"""
ids_str = "+".join(str(i) for i in ids)
url = f"https://api.ravelry.com/patterns.json?ids={ids_str}"
resp = requests.get(
url,
auth=(RAVELRY_USER, RAVELRY_PASS),
timeout=30,
)
resp.raise_for_status()
patterns_by_id = resp.json().get("patterns", {})
print(f"Step 2 complete: {len(patterns_by_id)} full pattern objects fetched")
return patterns_by_id
# ---------------------------------------------------------------
# Step 3 - Flatten into CSV rows, preserving rank
# ---------------------------------------------------------------
def flatten_pattern(rank: int, pattern: dict, fetched_at: str) -> dict:
"""Flatten a full pattern object into a single CSV row."""
# Nested objects - extract safely
author = pattern.get("pattern_author") or {}
craft = pattern.get("craft") or {}
ptype = pattern.get("pattern_type") or {}
yarn_weight = pattern.get("yarn_weight") or {}
first_photo = (pattern.get("photos") or [{}])[0] if pattern.get("photos") else {}
# Pattern categories - join names into a comma-separated string
categories = pattern.get("pattern_categories") or []
category_names = ", ".join(c.get("name", "") for c in categories if c.get("name"))
# Pattern attributes (e.g. "Colorwork", "Lace") - join permalinks
attributes = pattern.get("pattern_attributes") or []
attribute_names = ", ".join(a.get("permalink", "") for a in attributes)
# Needle sizes - join into readable string
needle_sizes = pattern.get("pattern_needle_sizes") or []
needles_str = ", ".join(
n.get("name", "") for n in needle_sizes if n.get("name")
)
return {
"rank": rank,
"id": pattern.get("id"),
"name": pattern.get("name"),
"permalink": pattern.get("permalink"),
"ravelry_url": f"https://www.ravelry.com/patterns/library/{pattern.get('permalink')}",
"free": pattern.get("free"),
"price": pattern.get("price"),
"currency": pattern.get("currency"),
"currency_symbol": pattern.get("currency_symbol"),
"downloadable": pattern.get("downloadable"),
"ravelry_download": pattern.get("ravelry_download"),
"pdf_url": pattern.get("pdf_url"),
"published": pattern.get("published"),
"created_at": pattern.get("created_at"),
"updated_at": pattern.get("updated_at"),
"rating_average": pattern.get("rating_average"),
"rating_count": pattern.get("rating_count"),
"difficulty_average": pattern.get("difficulty_average"),
"difficulty_count": pattern.get("difficulty_count"),
"favorites_count": pattern.get("favorites_count"),
"projects_count": pattern.get("projects_count"),
"queued_projects_count": pattern.get("queued_projects_count"),
"comments_count": pattern.get("comments_count"),
"gauge": pattern.get("gauge"),
"gauge_divisor": pattern.get("gauge_divisor"),
"gauge_pattern": pattern.get("gauge_pattern"),
"gauge_description": pattern.get("gauge_description"),
"row_gauge": pattern.get("row_gauge"),
"yardage": pattern.get("yardage"),
"yardage_max": pattern.get("yardage_max"),
"yardage_description": pattern.get("yardage_description"),
"sizes_available": pattern.get("sizes_available"),
"yarn_weight": yarn_weight.get("name"),
"yarn_weight_description": pattern.get("yarn_weight_description"),
"craft": craft.get("name"),
"pattern_type": ptype.get("name"),
"categories": category_names,
"attributes": attribute_names,
"needle_sizes": needles_str,
"designer_id": author.get("id"),
"designer_name": author.get("name"),
"designer_permalink": author.get("permalink"),
"designer_favorites": author.get("favorites_count"),
"designer_pattern_count": author.get("patterns_count"),
"photo_url": first_photo.get("medium_url"),
"photo_square_url": first_photo.get("square_url"),
"fetched_at": fetched_at,
}
def build_csv(ranked_ids: list, patterns_by_id: dict, fetched_at: str) -> str:
"""Build CSV string from ranked IDs + detail lookup. Rank is preserved."""
rows = []
for rank, pattern_id in enumerate(ranked_ids, start=1):
# Ravelry returns the patterns dict keyed by string id
pattern = patterns_by_id.get(str(pattern_id)) or patterns_by_id.get(pattern_id)
if not pattern:
print(f"Warning: no detail found for id {pattern_id}, skipping")
continue
rows.append(flatten_pattern(rank, pattern, fetched_at))
if not rows:
raise ValueError("No rows to write - pattern detail lookup returned empty")
buf = io.StringIO()
writer = csv.DictWriter(buf, fieldnames=list(rows[0].keys()))
writer.writeheader()
writer.writerows(rows)
return buf.getvalue()
# ---------------------------------------------------------------
# S3 - save CSV
# ---------------------------------------------------------------
def save_to_s3(csv_content: str, fetched_at_ts: str) -> str:
key = f"ravelry/ravelry_{fetched_at_ts}.csv"
s3.put_object(
Bucket=S3_BUCKET,
Key=key,
Body=csv_content.encode("utf-8"),
ContentType="text/csv",
)
print(f"Saved to s3://{S3_BUCKET}/{key}")
return key
# ---------------------------------------------------------------
# SES - email with CSV attachment
# ---------------------------------------------------------------
def send_email_ses(csv_content: str, s3_key: str, row_count: int):
filename = s3_key.split("/")[-1]
now_label = datetime.now(timezone.utc).strftime("%Y-%m-%d")
msg = MIMEMultipart()
msg["Subject"] = f"Ravelry Top Patterns - {now_label}"
msg["From"] = EMAIL_FROM
msg["To"] = EMAIL_TO
msg.attach(MIMEText(
f"Daily Ravelry popular patterns snapshot attached.\n\n"
f"Patterns: {row_count}\n"
f"File: {filename}\n"
f"S3 path: s3://{S3_BUCKET}/{s3_key}\n"
f"Fetched at: {datetime.now(timezone.utc).isoformat()} UTC",
"plain"
))
part = MIMEBase("application", "octet-stream")
part.set_payload(csv_content.encode("utf-8"))
encoders.encode_base64(part)
part.add_header("Content-Disposition", f"attachment; filename={filename}")
msg.attach(part)
ses.send_raw_email(
Source=EMAIL_FROM,
Destinations=[EMAIL_TO],
RawMessage={"Data": msg.as_string()},
)
print(f"Email sent to {EMAIL_TO}")
# ---------------------------------------------------------------
# Lambda entry point
# ---------------------------------------------------------------
def lambda_handler(event, context):
fetched_at = datetime.now(timezone.utc).isoformat()
fetched_at_ts = datetime.now(timezone.utc).strftime("%Y%m%d_%H%M%S")
# Step 1 - ranked IDs from search
ranked_ids = fetch_ranked_ids()
# Step 2 - full pattern details via /patterns.json?ids=
patterns_by_id = fetch_pattern_details(ranked_ids)
# Step 3 - flatten to CSV, rank preserved from step 1 order
csv_content = build_csv(ranked_ids, patterns_by_id, fetched_at)
row_count = csv_content.count("\n") - 1 # subtract header row
# Save to S3 and email
s3_key = save_to_s3(csv_content, fetched_at_ts)
send_email_ses(csv_content, s3_key, row_count)
return {
"statusCode": 200,
"body": f"Done. {row_count} patterns saved to {s3_key}"
}The data is nicely formatted in a CSV file and emailed to me. I’ll be digging into the data on and off. Here’s a collection of questions on the top of my head I’m interested in.
- How many patterns are free vs paid?
- How long does a pattern stay popular?
- Seasonal trends? Hats in winter, what are people making in the summer?
- petiteknit is the Taylor Swift of knitting patterns, with 1.2M followers on Instagram and an impressiv catalogue of 50+ patterns, let’s quantify that popularity!
Thanks for being with me on this adventure!
[1] Credit to datasock for the original idea. Proof that page 4 of Google is still worth a scroll.